Beautiful plots while simulating loss in two-part procrustes problem
 Today I was working on a two-part procrustes problem and wanted to find out why my minimization algorithm sometimes does not converge properly or renders unexpected results. The loss function to be minimized is
Today I was working on a two-part procrustes problem and wanted to find out why my minimization algorithm sometimes does not converge properly or renders unexpected results. The loss function to be minimized is
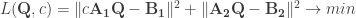
with 

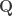
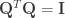
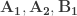



By plugging 
When trying to find out why the algorithm to minimize
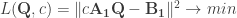
Here,
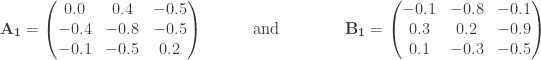
as input matrices. Generating many random rotation matrices

This is a well behaved relation, for each scaling parameter


and the following R-code.
# trace function
tr <- function(X) sum(diag(X))
# random matrix type 1
rmat_1 <- function(n=3, p=3, min=-1, max=1){
matrix(runif(n*p, min, max), ncol=p)
}
# random matrix type 2, sparse
rmat_2 <- function(p=3) {
diag(p)[, sample(1:p, p)]
}
# generate random rotation matrix Q. Based on Q find
# optimal scaling factor c and calculate loss function value
#
one_sample <- function(n=2, p=2)
{
Q <- mixAK::rRotationMatrix(n=1, dim=p) %*% # random rotation matrix det(Q) = 1
diag(sample(c(-1,1), p, rep=T)) # additional reflections, so det(Q) in {-1,1}
s <- tr( t(Q) %*% t(A1) %*% B1 ) / norm(A1, "F")^2 # scaling factor c
rss <- norm(s*A1 %*% Q - B1, "F")^2 + # get residual sum of squares
norm(A2 %*% Q - B2, "F")^2
c(s=s, rss=rss)
}
# find c and rss or many random rotation matrices
#
set.seed(10) # nice case for 3 x 3
n <- 3
p <- 3
A1 <- round(rmat_1(n, p), 1)
B1 <- round(rmat_1(n, p), 1)
A2 <- rmat_2(p)
B2 <- rmat_2(p)
x <- plyr::rdply(40000, one_sample(3,3))
plot(x$s, x$rss, pch=16, cex=.4, xlab="c", ylab="L(Q)", col="#00000010")
This time the result turns out to be very different and … beautiful :)

Here, we do not have a one to one relation between the scaling parameter and the loss function any more. I do not quite know what to make of this yet. But for now I am happy that it has aestethic value. Below you find some more beautiful graphics with different matrices as inputs.

Cheers!
Filed under: R / R-Code | 4 Comments
Feeds
Authors
Ecosia – eco-friendly web search

-

 Mark Heckmann’s blog
Mark Heckmann’s blog- Productivity: Markdown and R code in emails with Markdown Here
- Introduction to OpenRepGrid at the University of Barcelona
- Biennial EPCA Conference 2014 in Brno
- Werbung mit „harten“ Fakten – und warum man am Ende doch nicht schlauer ist als vorher
- 20th International Congress of Personal Construct Psychology in Sydney
- Erhalt des Berninghausenpreises für hervorragende Lehre
- 11th EPCA Biennial Conference in Dublin
- Karriere vs. Wissenschaft – Zur Verbesserung der Bedingungen für den wissenschaftlichen Nachwuchs
- Psychologie und LaTex – Literaturverzeichnisse im DGPs-Stil
- Zotero to LaTex Workflow
- R-help latest postings
- An error has occurred; the feed is probably down. Try again later.
Terms of use
The contents of the "R" you ready? blog are offered under a creative commons license.

Hi Mark, I try to run your syntax but R returns an error: could not find function “rdply”
So, probably one or more packages are required. If so, which are these?
Regards,
Eric
Hi Eric, you must load the ‘plyr’ package. I fixed it in the code. Thanks.
Hi Mark, I’m Brand new to R and just started blogging about it as well to help me remember/learn it. Thanks for your blog. Is there a contact page on your wordpress site? I couldn’t find one.
I found you R Google search blog incredibly helpful, and had a question, but i think the comments were closed. https://ryouready.wordpress.com/2009/01/01/r-retrieving-information-from-google-with-rcurl-package/.
I recently used it to grab all locations of a particular company across the US. I was curious if there was way to get to page 2 of Google using that code?
Thanks again,
Hi,
glad that you like the site:) Concerning Google, you can pass the ‘start’ parameter in the GET request, e.g. ‘start=10’ to get the second page. If you are not familiaer with the structure of GET requests, you may want to read about that first..
HTH
Bests
Mark